Every website relies on Google to some extent. It’s simple: your pages get indexed by Google, which makes it possible for people to find you. That’s the way things should go.
However, that’s not always the case. Many pages never get indexed by Google.
If you work with a website, especially a large one, you’ve probably noticed that not every page on your website gets indexed, and many pages wait for weeks before Google picks them up.
Various factors contribute to this issue, and many of them are the same factors that are mentioned with regard to ranking — content quality and links are two examples. Sometimes, these factors are also very complex and technical. Modern websites that rely heavily on new web technologies have notoriously suffered from indexing issues in the past, and some still do.
Many SEOs still believe that it’s the very technical things that prevent Google from indexing content, but this is a myth. While it’s true that Google might not index your pages if you don’t send consistent technical signals as to which pages you want indexed or if you have insufficient crawl budget, it’s just as important that you’re consistent with the quality of your content.
Most websites, big or small, have lots of content that should be indexed — but isn’t. And while things like JavaScript do make indexing more complicated, your website can suffer from serious indexing issues even if it’s written in pure HTML. In this post, let’s address some of the most common issues, and how to mitigate them.
Reasons why Google isn’t indexing your pages
Using a custom indexing checker tool, I checked a large sample of the most popular e-commerce stores in the US for indexing issues. I discovered that, on average, 15% of their indexable product pages cannot be found on Google.
That result was extremely surprising. What I needed to know next was “why”: what are the most common reasons why Google decides not to index something that should technically be indexed?
Google Search Console reports several statuses for unindexed pages, like “Crawled – currently not indexed” or “Discovered – currently not indexed”. While this information doesn’t explicitly help address the issue, it’s a good place to start diagnostics.
Top indexing issues
Based on a large sample of websites I collected, the most popular indexing issues reported by Google Search Console are:
1. “Crawled – currently not indexed”
In this case, Google visited a page but didn’t index it.
Based on my experience, this is usually a content quality issue. Given the e-commerce boom that’s currently happening, we can expect Google to get pickier when it comes to quality. So if you notice your pages are “Crawled – currently not indexed”, make sure the content on those pages is uniquely valuable:
-
Use unique titles, descriptions, and copy on all indexable pages.
-
Avoid copying product descriptions from external sources.
-
Use canonical tags to consolidate duplicate content.
-
Block Google from crawling or indexing low-quality sections of your website by using the robots.txt file or the noindex tag.
If you are interested in the topic, I recommend reading Chris Long’s Crawled — Currently Not Indexed: A Coverage Status Guide.
2. “Discovered – currently not indexed”
This is my favorite issue to work with, because it can encompass everything from crawling issues to insufficient content quality. It’s a massive problem, particularly in the case of large e-commerce stores, and I’ve seen this apply to tens of millions of URLs on a single website.
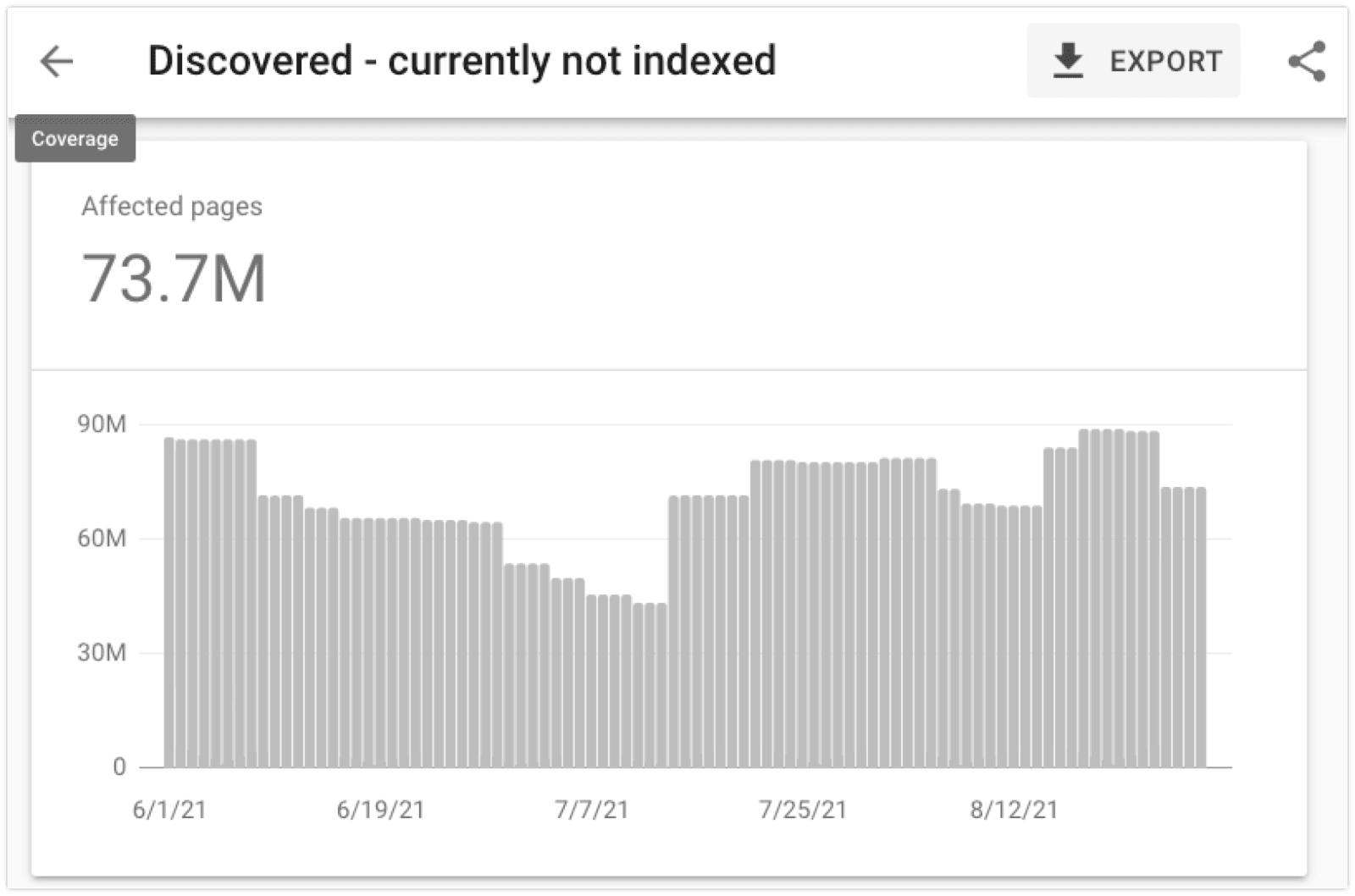
Google may report that e-commerce product pages are “Discovered – currently not indexed” because of:
-
A crawl budget issue: there may be too many URLs in the crawling queue and these may be crawled and indexed later.
-
A quality issue: Google may think that some pages on that domain aren’t worth crawling and decide not to visit them by looking for a pattern in their URL.
Dealing with this problem takes some expertise. If you find out that your pages are “Discovered – currently not indexed”, do the following:
-
Identify if there are patterns of pages falling into this category. Maybe the problem is related to a specific category of products and the whole category isn’t linked internally? Or maybe a huge portion of product pages are waiting in the queue to get indexed?
-
Optimize your crawl budget. Focus on spotting low-quality pages that Google spends a lot of time crawling. The usual suspects include filtered category pages and internal search pages — these pages can easily go into tens of millions on a typical e-commerce site. If Googlebot can freely crawl them, it may not have the resources to get to the valuable stuff on your website indexed in Google.
During the webinar “Rendering SEO”, Martin Splitt of Google gave us a few hints on fixing the Discovered not indexed issue. Check it out if you want to learn more.
3. “Duplicate content”
This issue is extensively covered by the Moz SEO Learning Center. I just want to point out here that duplicate content may be caused by various reasons, such as:
-
Language variations (e.g. English language in the UK, US, or Canada). If you have several versions of the same page that are targeted at different countries, some of these pages may end up unindexed.
-
Duplicate content used by your competitors. This often occurs in the e-commerce industry when several websites use the same product description provided by the manufacturer.
Besides using rel=canonical, 301 redirects, or creating unique content, I would focus on providing unique value for the users. Fast-growing-trees.com would be an example. Instead of boring descriptions and tips on planting and watering, the website allows you to see a detailed FAQ for many products.
Also, you can easily compare between similar products.
For many products, it provides an FAQ. Also, every customer can ask a detailed question about a plant and get the answer from the community.

How to check your website’s index coverage
You can easily check how many pages of your website aren’t indexed by opening the Index Coverage report in Google Search Console.
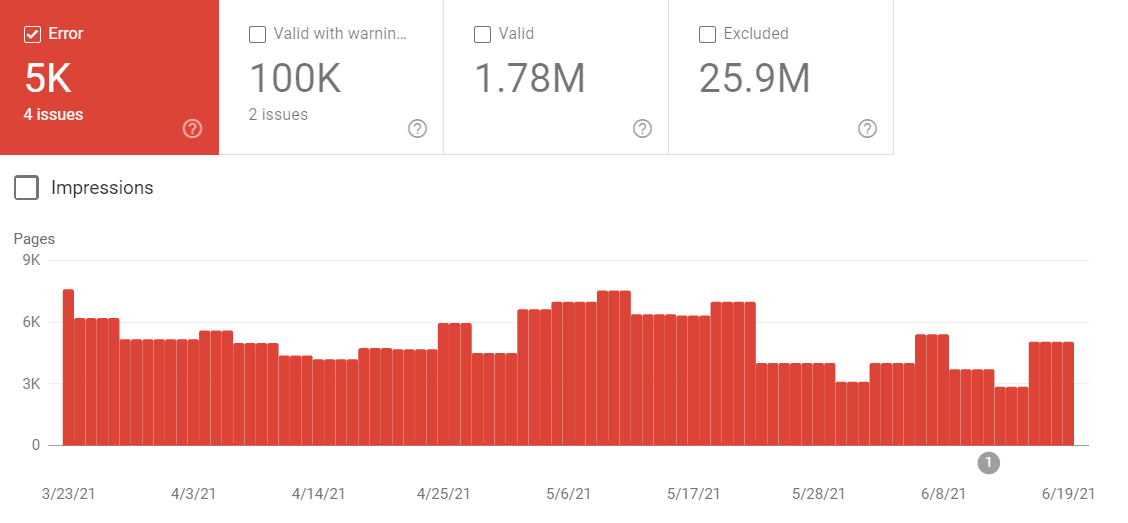
The first thing you should look at here is the number of excluded pages. Then try to find a pattern — what types of pages don’t get indexed?
If you own an e-commerce store, you’ll most probably see unindexed product pages. While this should always be a warning sign, you can’t expect to have all of your product pages indexed, especially with a large website. For instance, a large e-commerce store is bound to have duplicate pages and expired or out-of-stock products. These pages may lack the quality that would put them at the front of Google’s indexing queue (and that’s if Google decides to crawl these pages in the first place).
In addition, large e-commerce websites tend to have issues with crawl budget. I’ve seen cases of e-commerce stores having more than a million products while 90% of them were classified as “Discovered – currently not indexed”. But if you see that important pages are being excluded from Google’s index, you should be deeply concerned.
How to increase the probability Google will index your pages
Every website is different and may suffer from different indexing issues. However, here are some of the best practices that should help your pages get indexed:
1. Avoid the “Soft 404” signals
Make sure your pages don’t contain anything that may falsely indicate a soft 404 status. This includes anything from using “Not found” or “Not available” in the copy to having the number “404” in the URL.
2. Use internal linking
Internal linking is one of the key signals for Google that a given page is an important part of the website and deserves to be indexed. Leave no orphan pages in your website’s structure, and remember to include all indexable pages in your sitemaps.
3. Implement a sound crawling strategy
Don’t let Google crawl cruft on your website. If too many resources are spent crawling the less valuable parts of your domain, it might take too long for Google to get to the good stuff. Server log analysis can give you the full picture of what Googlebot crawls and how to optimize it.
4. Eliminate low-quality and duplicate content
Every large website eventually ends up with some pages that shouldn’t be indexed. Make sure that these pages don’t find their way into your sitemaps, and use the noindex tag and the robots.txt file when appropriate. If you let Google spend too much time in the worst parts of your site, it might underestimate the overall quality of your domain.
5. Send consistent SEO signals.
One common example of sending inconsistent SEO signals to Google is altering canonical tags with JavaScript. As Martin Splitt of Google mentioned during JavaScript SEO Office Hours, you can never be sure what Google will do if you have one canonical tag in the source HTML, and a different one after rendering JavaScript.
The web is getting too big
In the past couple of years, Google has made giant leaps in processing JavaScript, making the job of SEOs easier. These days, it’s less common to see JavaScript-powered websites that aren’t indexed because of the specific tech stack they’re using.
But can we expect the same to happen with the indexing issues that aren’t related to JavaScript? I don’t think so.
The internet is constantly growing. Every day new websites appear, and existing websites grow.
Can Google deal with this challenge?
This question appears every once in a while. I like quoting Google here:
“Google has a finite number of resources, so when faced with the nearly infinite quantity of content that’s available online, Googlebot is only able to find and crawl a percentage of that content. Then, of the content we’ve crawled, we’re only able to index a portion.”
To put it differently, Google is able to visit just a portion of all pages on the web and index an even smaller portion. And even if your website is amazing, you should keep that in mind.
Google probably won’t visit every page of your website, even if it’s relatively small. Your job is to make sure that Google can discover and index pages that are essential for your business.
If you liked Why Getting Indexed by Google is so Difficult by Tomek Rudzki Then you'll love Miami SEO Expert